Product management for AI products - old wine in new bottle?
Published:
Netflix recently posted a job opening for an AI Product Manager role with a staggering annual salary of up to $900,000. The question arises: why such a high compensation for an AI PM? When was the last time a Product Manager got paid so high?

The answer lies in the specialized skill set required for product management in the realm of AI. The traditional principles and experiences in product management for standard software products do not suffice for AI products. Product management in AI development demands a significant upgrade.
Before delving into the specifics of 'what' product management skills to enhance and 'how' to upgrade them to thrive in the AI product era, it's crucial to address the 'why.' Why do traditional product management methodologies and approaches fall short in the AI-first world? Let's explore the fundamental changes from traditional software to AI software that necessitate the evolution of product management skills:
-
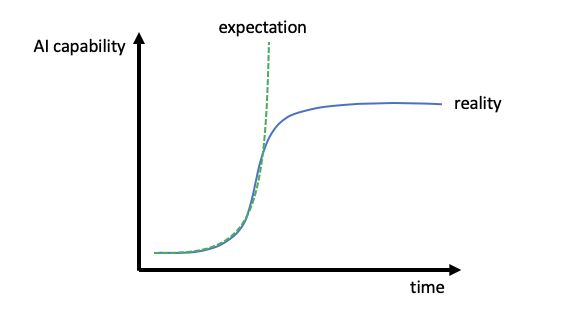
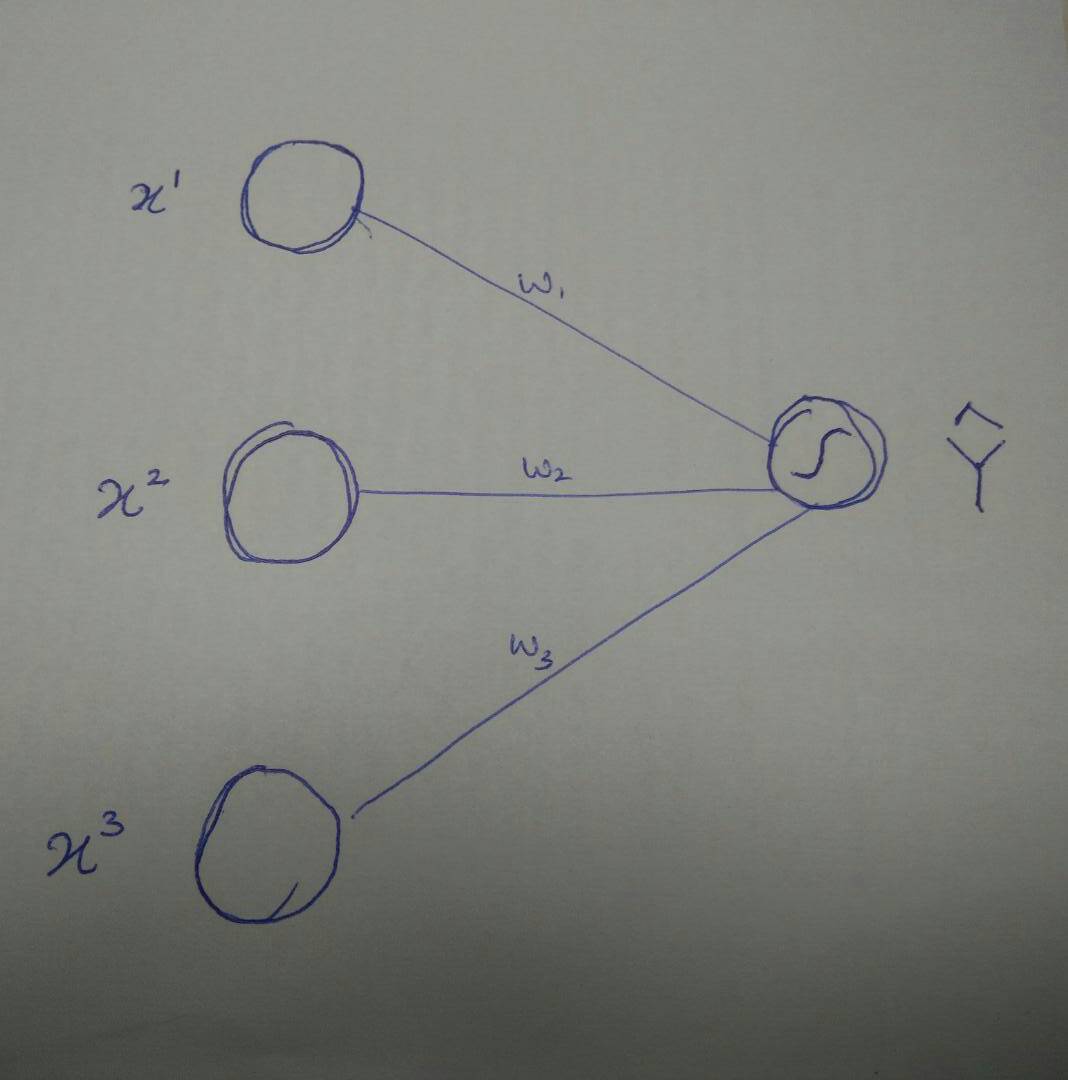
Stochastic vs Deterministic: Traditional software (referred to as software 1.0) operates deterministically, meaning it consistently produces the same output for a given system and input. In contrast, AI software (referred to as software 2.0) is stochastic, meaning it can yield varying outputs for the same system and input.
As a product manager, meticulous control over the user experience is paramount, especially to prevent negative user experiences. In the realm of software 1.0, this entails thorough scenario planning within the Product Requirements Document (PRD) to anticipate and design for potential errors. Once the software undergoes comprehensive testing, scenarios that pass ensure a reliable user experience in production, barring any unforeseen bugs.
However, the landscape shifts with AI software (software 2.0). Even after rigorous testing, AI systems may still generate incorrect responses due to their stochastic nature. Such occurrences are not considered bugs but rather inherent to the probabilistic framework of AI software. Acknowledging that no AI system achieves perfect accuracy, product managers must proactively devise user experiences capable of managing errors and gracefully handling failures. This necessitates a specialized understanding of AI design processes for product managers to effectively navigate this terrain.
-
Designing for loops (control loop, feedback loop, human-in-the-loop): Given the stochastic nature of AI systems, errors are inevitable. As a product manager, it's imperative to establish control loops to swiftly determine whether the AI's output is beneficial to the end user. If not, end users should be empowered to take control of the system to override the AI's decisions, stop AI recommendations.
Similarly, the product team must institute feedback loops for each AI feature to assess its efficacy for end users. This involves gathering data across various scenarios to ascertain when the feature performs optimally and when it falters.
Additionally, designing for humans-in-the-loop is crucial, enabling the seamless transition of control from AI systems to human operators when necessary.
-
Data Collection: It's widely recognized that AI relies heavily on data. However, the responsibility of data collection doesn't fall on AI scientists; rather, it lies with the product team. Why? Because the product team holds ownership of the product, making them best suited to embed the necessary instrumentation for data collection.
This is where PMs need to understand the lingo of data systems and work with data engineering teams to create roadmaps & sprints for data collection. In large AI first MNCs, this is a very specialized role called Data PM.
- Introducing Users to AI: When integrating AI into your products for the first time, it's vital to introduce AI to your users delicately. Setting the right expectations and assuring users that they can regain control if they're uncomfortable is essential. Achieving this demands the creation of a highly specialized flows & UX.
-
Economics of AI: AI constitutes a costly endeavor, encompassing expenses in data acquisition, cleaning, storage to create datasets; computational resources, and talent acquisition. Given the high costs involved, not every potential use case justifies the investment. Hence, it's imperative to select use cases judiciously.
Within a company, the business team comprehends business dynamics but often lacks technical expertise, while individual contributors (ICs) in the AI team possess technical proficiency but may not grasp business intricacies. In this landscape, product managers play a pivotal role, bridging the gap between technology, user needs, and business objectives. Consequently, the responsibility of evaluating and determining the feasibility & viability of AI use cases predominantly falls on the shoulders of product managers.
- The AI development process is very different: The transition
from
traditional
software development (Software 1.0) to AI-driven systems (Software 2.0)
introduces
significant differences in how product management approaches roadmaps and
timelines.
Here are some implications for product owners:
- Uncertainty in Improvement: Unlike traditional software where incremental improvements are often achievable by addressing specific issues or corner cases, AI-driven systems may hit performance plateaus where further improvements are challenging. This uncertainty must be factored into product roadmaps and timelines, as achieving desired performance levels may require more extensive reevaluation and experimentation.
- Extended Development Cycles: Improving AI-driven systems often involves revisiting the underlying algorithms, data pipelines, or model architectures, which can be time-consuming processes. Product owners need to allocate sufficient time in their roadmaps for research, experimentation, and validation of new approaches, potentially extending development cycles beyond what is typical for traditional software updates.
- Resource Allocation: Given the longer development cycles associated with improving AI systems, product owners may need to allocate additional resources, both in terms of engineering talent and computational resources. This may require reprioritizing other initiatives or increasing investment in AI research and development to meet performance targets within the desired timeframe.